
Perkembangan AI generatif membuat semakin banyak pengguna ingin menjalankan Large Language Model (LLM) langsung di perangkat mereka sendiri. Alasannya sederhana: lebih privat, lebih cepat, dan tidak selalu bergantung pada cloud.
Namun menjalankan model AI besar secara lokal bukan hal mudah. Banyak model modern membutuhkan VRAM besar dan resource hardware tinggi. Di sinilah NVIDIA GeForce RTX dan AI PC mulai memainkan peran penting.
Melalui seri AI Decoded, NVIDIA menjelaskan bagaimana aplikasi LM Studio memanfaatkan RTX AI acceleration untuk membantu pengguna menjalankan LLM secara lokal dengan lebih efisien menggunakan teknologi GPU offloading.
Bagi developer, content creator, hingga AI enthusiast, kombinasi LM Studio dan RTX AI PC mulai menjadi salah satu workflow AI lokal paling populer saat ini.
Apa Itu LM Studio?
LM Studio adalah aplikasi desktop yang memungkinkan pengguna menjalankan dan meng-host model AI secara lokal di PC atau laptop mereka. Platform ini dibangun di atas llama.cpp sehingga sudah dioptimalkan untuk GPU NVIDIA GeForce RTX dan NVIDIA RTX workstation.
Dengan LM Studio, pengguna dapat:
- menjalankan local LLM,
- membuat AI chatbot pribadi,
- melakukan document summarization,
- menjalankan AI coding assistant,
- hingga membuat local AI workflow tanpa cloud.
LM Studio juga mendukung API lokal yang kompatibel dengan OpenAI API sehingga mudah diintegrasikan ke berbagai aplikasi dan workflow developer.
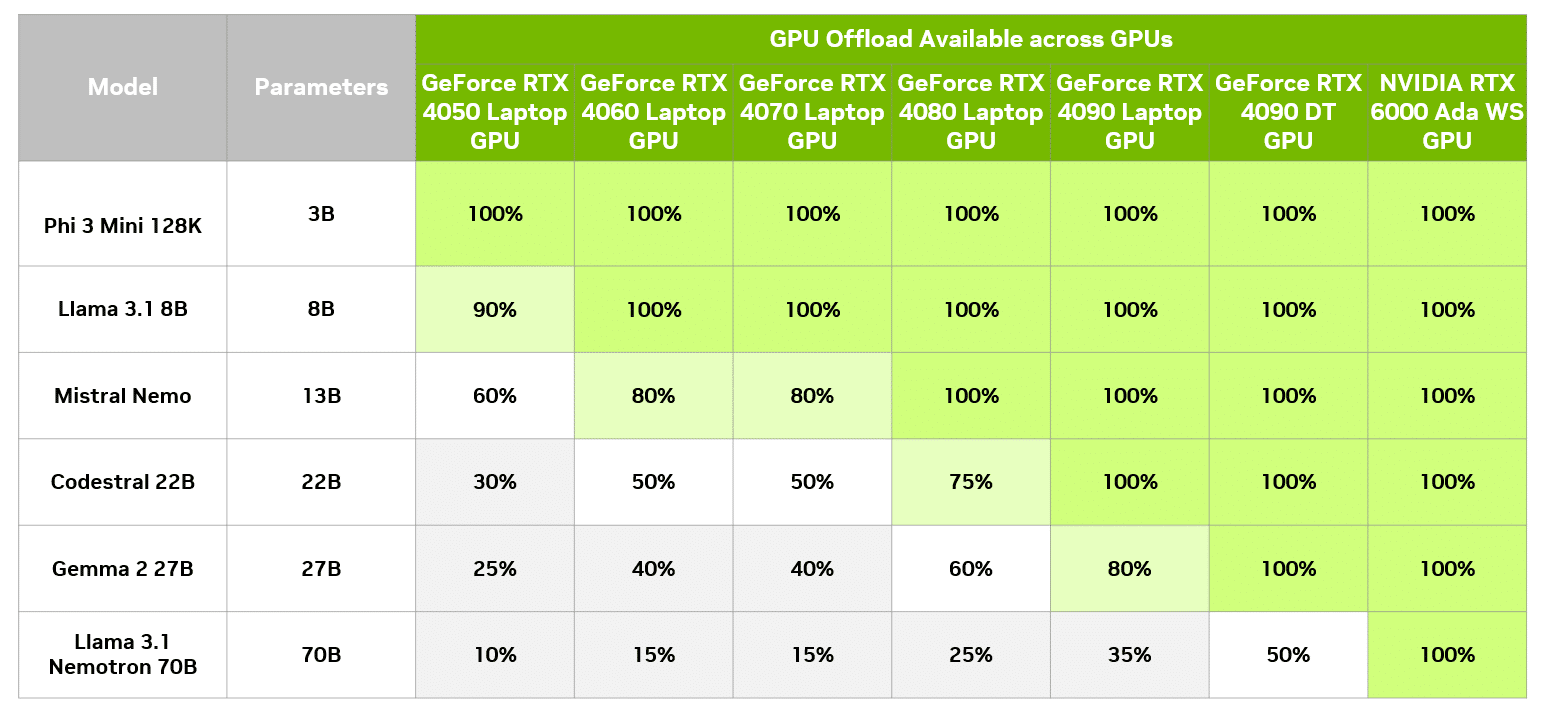
NVIDIA GeForce RTX dan GPU Offloading Jadi Kunci
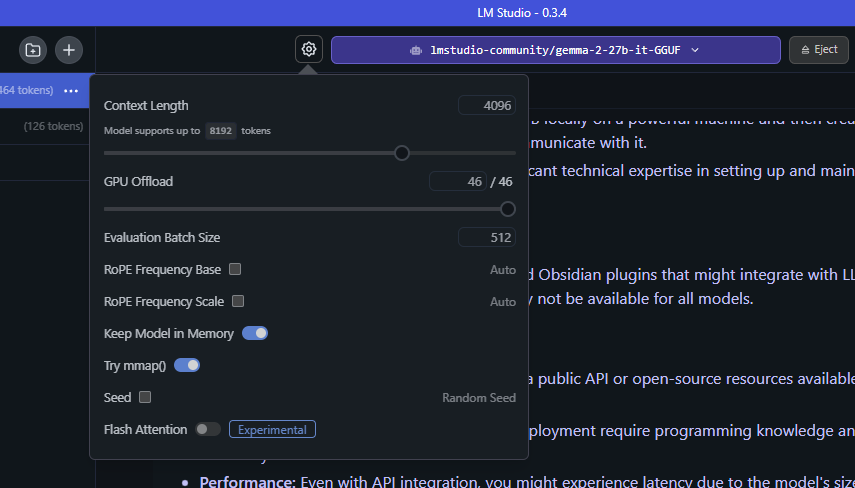
Salah satu pembahasan utama NVIDIA adalah GPU offloading.
Teknik ini memungkinkan sebagian model AI diproses menggunakan GPU RTX sementara sebagian lain tetap berjalan di CPU. Dengan cara ini, model besar yang biasanya membutuhkan VRAM sangat tinggi tetap bisa dijalankan di AI PC consumer.
Contohnya model seperti Gemma 2 27B yang sebelumnya sulit dijalankan penuh di GPU mainstream kini dapat berjalan lebih optimal dengan bantuan RTX acceleration.
Kenapa AI PC Penting untuk Local LLM?
AI PC modern kini mulai dirancang khusus untuk workload AI generatif.
NVIDIA menjelaskan bahwa GeForce RTX memiliki Tensor Core khusus AI acceleration yang membantu mempercepat inferensi model AI secara signifikan.
Keuntungan menjalankan AI lokal di RTX AI PC antara lain:
Privasi Lebih Aman
Semua proses AI berjalan langsung di perangkat tanpa harus mengirim data ke cloud.
Bisa Digunakan Offline
Local LLM tetap bisa digunakan meski tanpa koneksi internet.
Performa Lebih Cepat
GPU RTX mampu mempercepat token generation dibanding CPU-only inference.
Workflow Lebih Fleksibel
Developer bisa menghubungkan LM Studio dengan aplikasi lain menggunakan API lokal.
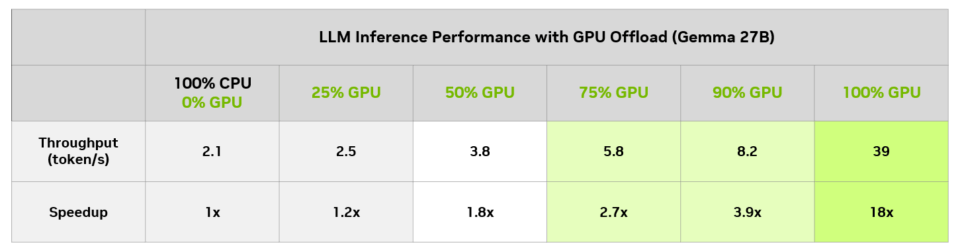
CUDA 12.8 dan Performa LLM yang Lebih Tinggi
Versi terbaru LM Studio juga mulai memanfaatkan CUDA 12.8 untuk meningkatkan performa RTX GPU.
NVIDIA menyebut beberapa optimasi terbaru mencakup:
- CUDA Graph enablement,
- Flash Attention CUDA kernels,
- optimasi throughput AI,
- dan kompatibilitas RTX Blackwell terbaru.
Menurut NVIDIA, kombinasi optimasi ini mampu meningkatkan throughput AI hingga sekitar 35% pada beberapa model tertentu.
RTX AI PC Kini Jadi Playground AI Lokal
Perkembangan local AI membuat RTX AI PC kini bukan hanya digunakan untuk gaming.
Banyak pengguna mulai memakai GPU RTX untuk:
- AI chatbot lokal,
- AI coding,
- RAG workflow,
- generative AI,
- AI agent,
- hingga AI automation.
Komunitas Reddit bahkan memperlihatkan benchmark local LLM yang mampu menghasilkan lebih dari 200 token per detik menggunakan RTX 5090 di LM Studio.
Hal ini menunjukkan bagaimana GPU consumer modern kini mulai mendekati performa workstation AI skala kecil.
Komunitas AI Mulai Fokus ke Workflow Lokal
Diskusi komunitas LocalLLaMA menunjukkan semakin banyak pengguna berpindah ke AI lokal karena alasan privasi dan kontrol data.
LM Studio menjadi populer karena lebih mudah digunakan dibanding setup AI tradisional berbasis command line yang kompleks.
Bahkan pengguna non-developer kini mulai bisa menjalankan local AI hanya dengan beberapa klik menggunakan RTX AI PC.
NVIDIA dan Masa Depan AI Personal
NVIDIA sendiri semakin agresif mendorong konsep personal AI workstation melalui RTX AI PC.
Melalui TensorRT, CUDA, Tensor Core, dan berbagai optimasi AI lainnya, RTX GPU kini menjadi salah satu fondasi utama perkembangan local generative AI modern.
Tren ini juga memperlihatkan bahwa masa depan AI kemungkinan tidak hanya berada di cloud, tetapi juga berjalan langsung di perangkat pribadi pengguna.
FAQ Seputar NVIDIA, GeForce RTX, dan LM Studio
Apa itu LM Studio?
LM Studio adalah aplikasi desktop untuk menjalankan Large Language Model (LLM) secara lokal di PC atau laptop.
Kenapa NVIDIA GeForce RTX penting untuk LM Studio?
GPU RTX memiliki Tensor Core dan CUDA acceleration yang membantu mempercepat inferensi AI lokal.
Apa itu GPU offloading?
GPU offloading adalah teknik membagi proses AI antara GPU dan CPU agar model besar tetap bisa berjalan di hardware consumer.
Apakah AI PC cocok untuk local AI?
Ya. AI PC modern dirancang untuk workload AI seperti local LLM, generative AI, dan AI acceleration.
Apakah local AI lebih aman dibanding cloud AI?
Untuk banyak kasus, ya. Karena data dan percakapan tetap berada di perangkat pengguna.
Local LLM dan RTX AI PC Akan Semakin Populer
Perkembangan LM Studio menunjukkan bahwa AI kini mulai bergerak menuju pengalaman yang lebih personal dan lokal.
Dengan dukungan NVIDIA GeForce RTX dan AI PC modern, pengguna kini dapat menjalankan model AI canggih langsung di perangkat mereka sendiri tanpa harus bergantung penuh pada cloud service.
Bagi developer, kreator, maupun pengguna umum, kombinasi local AI dan RTX acceleration membuka peluang baru untuk workflow yang lebih cepat, privat, dan fleksibel.
Sumber Berita
- NVIDIA Blog – Accelerate Larger LLMs Locally on RTX With LM Studio
- NVIDIA Blog – LM Studio Accelerates LLM Performance With GeForce RTX GPUs
- NVIDIA Blog – RTX AI PCs Enhance Creating, Gaming and More
- NVIDIA Blog – AI Decoded RTX AI PC Series
- Reddit – GPT-OSS-20B Benchmark on RTX 5090 With LM Studio
- Reddit – Community Discussion About Local AI and LM Studio




Leave a Reply
You must be logged in to post a comment.